Im ersten Teil haben wir uns der korrekten Verwendung von NTP gewidmet. Sobald dies nun in den Hirnzellen Platz gefunden hat, wollen wir uns etwas technischer mit dem NTP Deamon und den wichtigsten Optionen beschäftigen. Ich beziehe mich in diesem Artikel – wie auch im ersten – zum Grossteil auf Erfahrungswerte. Sollten andere Meinungen kursieren, bin ich für Diskussionen immer zu haben.
Optionen von NTP
Um generell die verschiedenen Parameter zu verstehen, hier mal ein Output von «ntpq –p»:
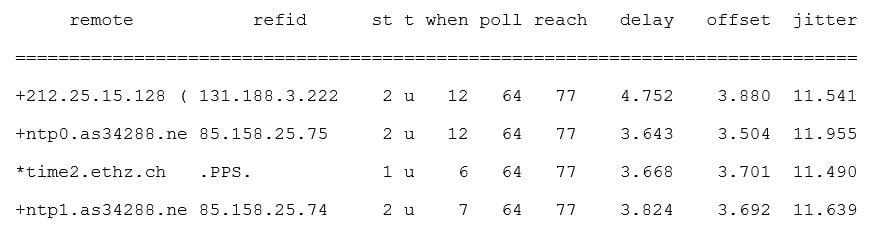
Die verschiedenen Parameter sind im Internet ausgiebig dokumentiert, jedoch möchte ich diese der Einfachheit halber hier ebenfalls kurz erklären. Wir sehen hier die 4 Server (0-3.ch.pool.ntp.org), welche in der Konfiguration angegeben sind. Das dürfte soweit aus dem ersten Artikel bekannt sein.
remote
Hostname/IP der konfigurierten Timesource.
* wird aktuell benutzt
+ wird miteinbezogen
– wird ignoriert
refid
Die Timesource unserer konfigurierten Timesource
stratum (st)
Das Stratum bezeichnet hierarchisch die Stufe des NTP Server. Visuelles Beispiel:
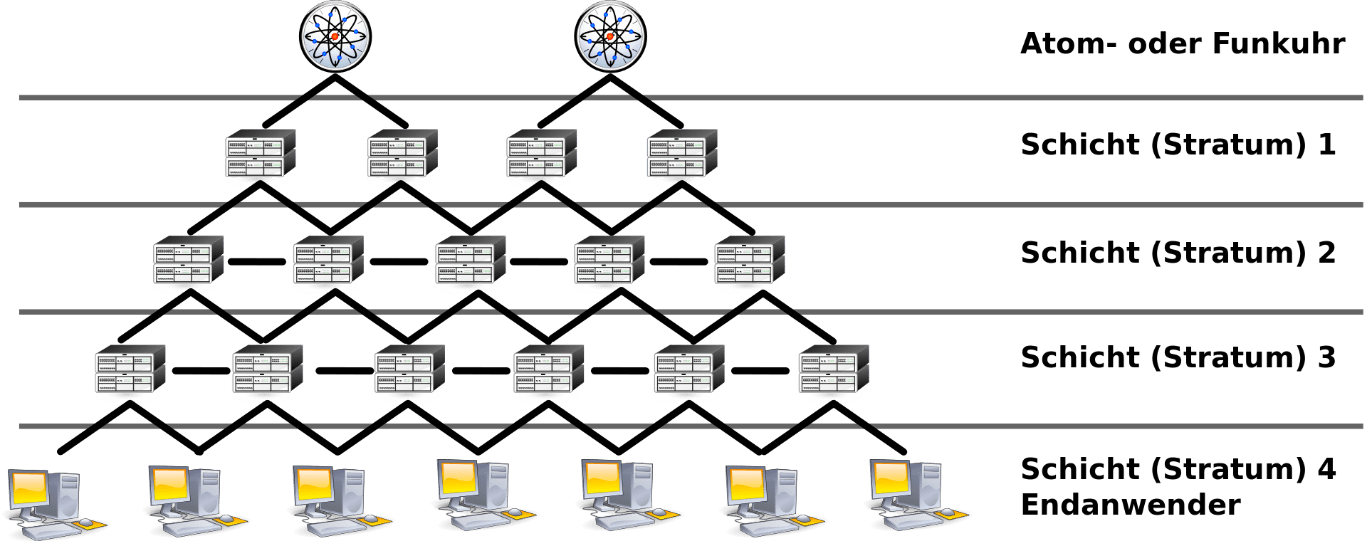
Im obigen Beispiel sehen wir einen Stratum-1-Server der ETH. Dieser ist direkt einer Stratum-0-Zeitquelle angeschlossen und hat deshalb keine IP als RefID hinterlegt, sondern “.PPS.”, welches den Typ des Zeitgebers bezeichnet, in diesem Fall eine Funkuhr.
Die ganze Geschichte geht bis Stratum 15, es gibt also insgesamt 16 Stufen. In der Praxis trifft man dies jedoch nie an, es sei denn man konfiguriert das manuell so.
t
Der Typ. In fast allen Fällen Unicast.
when
Zeit in Sekunden, wann die letzte Abfrage bei den Zeitquellen war.
poll
Interval, indem die Zeit abgefragt wird.
reach
Zeigt an, welche der letzten 8 Polls erfolgreich war. 377 heisst, alle waren erfolgreich. Diese Anzeige ist in Oktal. (8 Bit à 11111111)
11101111 bedeutet, dass der 5.-letzte Poll nicht erfolgreich war, die letzten 4 aber schon. Dies wird als Oktalzahl 357 dargestellt. So weiss ich mit dieser Angabe immer, welcher der letzten 8 Polls erfolgreich war. Weiter möchte ich mich hier nicht vertiefen, denn sonst wird daraus ein eigener Artikel 😉
delay
So lange hat es gedauert, das Paket zum NTP Server zu senden und zurück zu erhalten (RTT).
offset
So viele Millisekunden läuft die interne Uhr aktuell vor oder nach.
jitter
Definiert die Schwankungen der einzelnen Netzwerkabfragen (meist ausgelöst von Switch, Router, Firewall und deren Auslastungen). Einfach gesagt: Dauert der erste Ping zu einem bestimmten Gerät 2ms und der zweite 5ms, so habe ich eine Netzwerkschwankung. Genannt Jitter.
Wie funktioniert NTP Spoofing
Kommen wir nun zum spannenden Teil der Story: das Springen in der Zeit. Zugegeben, es wird nicht ganz so spektakulär wie es Christopher Nolan in «Interstellar» inszeniert, und ich werde hier auch nicht im Detail zeigen, wie es funktioniert. Wie man eine «Man in the Middle» Attacke auf ARP Basis ausführt, ist jedoch weitläufig bekannt. UDP-Protokolle sind allgemein anfälliger auf Angriffe aufgrund ihrer verbindungslosen Bauweise. In einem LAN lässt sich dies infolge dessen mit ARP Spoofing mit verhältnismässig simpeln Mitteln spoofen. Habe ich einen Rechner mit einem beliebigen Linux – nennen wir es für diesen Fall Kali Linux – sowie einem darauf laufenden NTP Server im Netzwerk platziert und das ARP Spoofing in-place, so kann ich als gefälschter NTP Server agieren und meine falsche Zeit an die Ziele weitergeben. Hat das Ziel nun nur eine oder 2 Zeitquellen hinterlegt, ist die Chance gross, dass meine falsche Zeit als die neue Realzeit akzeptiert wird. Die Folgen davon haben wir im ersten Artikel gesehen. Das wird dann ziemlich unschön.
Es gibt noch eine zweite Variante die Zeit aktiv anzugreifen. Es ist die Experten-Version, mit dem Tool Scapy. Mit Scapy lassen sich UDP-Pakete selber bauen und verändern. Das eröffnet nochmal ein ganz neues Thema, wer mehr darüber wissen will, kann sich gerne diesen Artikel genauer ansehen: scapy.readthedocs.io/en/latest/usage.html#fuzzing.
Und was hat das nun mit Security zu tun?
Sie mögen sich nun fragen, was daran gefährlich sein soll. Es ist ja schliesslich nur von intern realisierbar, also was soll das Ganze? Ich wechsle hier mal meinen Hut und beziehe mich auf grössere Unternehmen. Meiner Erfahrung nach sind die meisten internen Systeme von aussen schon sehr gut geschützt, vorausgesetzt die Konfiguration stimmt auch. In vielen Audits – und ich habe schon gefühlt hunderte hinter mir – werden keine schwerwiegenden äusseren Bedrohungen mehr gefunden. Findet man aussen nichts mehr, wird halt einfach intern weitergesucht. Wer hat welche Rechte? Werden diese Rechte wirklich gebraucht? Sind durch diese Rechte auch «Privilege Escalations» möglich?
Oft muss entweder diese Frage mit «Ja» beantwortet werden, oder diverse Mitarbeitende haben bereits mehr Rechte als sie benötigen. Man nehme als Beispiel Lernende. Diese wechseln von Abteilung zu Abteilung und müssen, um schlau arbeiten zu können, dieselben Rechte wie alle anderen im Team haben. So kommt es auch mal vor, dass ein Lehrabgänger ein Domain Admin ist, auf allen Linux Systemen Root Berechtigungen hat, über physischen RZ-Zutritt verfügt und Admin auf dem z/OS ist. Unrealistisch? Nein. Alles schon gesehen.
Wie entdecke und verhindere ich nun solche spassigen Geschichten? Zwei Themen dürften hier wichtig sein:
Authentication
NTP lässt sich seit NTPv4 über Autokey authentisieren. In Autokey wurden aber bereits wieder Schwachstellen entdeckt, welche das Protokoll nutzlos machen. Das Team hinter NTP hat zwar dafür einige Änderungen implementiert, welche Autokey wieder benutzbar machen (lists.ntp.org/pipermail/ntpwg/2011-August/001714.html). Jedoch ist es nur eine Frage der Zeit, bis auch dies wieder überholt ist und nicht mehr benutzt werden sollte. Autokey basiert auf der bekannten Public/Private Key Implementation und bietet einen ersten Layer an Schutz. Glücklicherweise ist auch schon der Nachfolger von Autokey in der Entwicklung: datatracker.ietf.org/doc/draft-ietf-ntp-using-nts-for-ntp/. Mit NTS soll dann auch NTP über TLS möglich sein. Es ist aktuell noch ein Draft und es sind noch nicht alle Punkte vollständig definiert. Bevor ich allerdings nur schon an eine Authentication denke, sollte ich erstmal eine schlaue Überwachung implementieren.
Monitoring
Ich kenne NTP aus einer Welt, in der 1ms Zeitdifferenz den Unterschied zwischen grüner und roter Lampe ausmachten. In dieser Welt wurde jeder Server, jeder Switch, jede Firewall aufs Genauste überwacht. Eine Abweichung von Millisekunden konnte bereits einen grossen Geldbetrag ausmachen. Aus welcher Welt das kommt, kann man sich denken 😉
Für einen Grossteil der Anwendungen ist dies jedoch schlicht übertrieben und eine Genauigkeit in Zehntelsekunden reicht bereits aus. Das ist mitunter der Grund, weshalb in diesen Anwendungen die Überwachung oft vernachlässigt wird. Es funktioniert auch weiterhin, wenn das System ein paar Sekunden oder gar Minuten daneben liegt. Das Thema ist aber nicht zu vernachlässigen. Es beginnt mit kleineren störenden Vorkommnissen. Man möchte ein Log ansehen und merkt nach einiger Zeit, dass da etwas nicht stimmen kann, beispielsweise ist die Zeit immer 2 Minuten versetzt. Dies kann je nach Fall dann einfach korrigiert werden. Was aber, wenn die Zeit eines Mailservers oder Mailgateways mehrere Minuten danebenliegt und ich muss beweisen können, dass beispielsweise eine Nachricht zu einer bestimmten Zeit rausgegangen ist? Viel Glück damit. Oder wenn der Commit auf einer Datenbank einige Minuten danebenliegt und ich im Nachhinein etwas beweisen möchte? Viel Spass damit.
Da einige der uns bekannten Produkte kein Monitoring mitliefern, ist dies manchmal nur via manuellem Scripting und Alerting zu realisieren. Meiner Meinung nach müsste das NTP Monitoring bereits in allen Anwendungen integriert sein, hier braucht es von den Herstellern auch ein Umdenken der Wichtigkeit und den Gefahren von NTP.
Schlusswort
Zugegeben, ich habe mich in der Vergangenheit etwas zu sehr mit NTP beschäftigt und beschäftigen müssen, weshalb ich eine etwas extreme Ansicht und Meinung dazu habe. Am Ende das Tages ist es die simpelste Lösung, die Zeit auf all meinen Systemen zu überwachen und zu alarmieren, sobald die Abweichung einen gewissen Threshold überschreitet. Dies können 10 oder auch 100 Millisekunden sein, das reicht bei fast allen Anwendungsfällen.
Es ist besser, intern eine genaue Zeit zu haben, welche einige Millisekunden von der externen abweicht, anstelle alle Geräte extern synchronisieren zu lassen. Deshalb empfiehlt es sich, intern ein paar NTP Server zu betreiben (Stratum 3), wobei sich nur einer davon nach aussen synchronisiert (Stratum 2), der Rest soll sich nur intern untereinander synchronisieren. So läuft mein gesamtes internes Netz mit derselben Uhrzeit.
Appendix
Chronyd habe ich in diesem Artikel absichtlich nicht behandelt, da aktuell alle unsere angebotenen Produkte mit dem NTP Daemon hantieren. Chronyd ist eine andere Implementation des NTP Daemons und wurde ab RedHat 7 eingeführt. Die Funktionen sind dieselben, die Genauigkeit der Synchronisation wird jedoch besser, insbesondere das Angleichen der Uhr bei grösseren Ungenauigkeiten. Da unsere Produkte «always-on» sind, eignet sich der ntpd besser.