„Montagmorgen, 9 Uhr. Die Support-Hotline glüht. Niemand kommt mehr auf SharePoint, Salesforce oder interne Tools. Der SASE-Dienst ist down – und plötzlich steht das Unternehmen still. Wie konnte das passieren? Und was tun wir jetzt?“
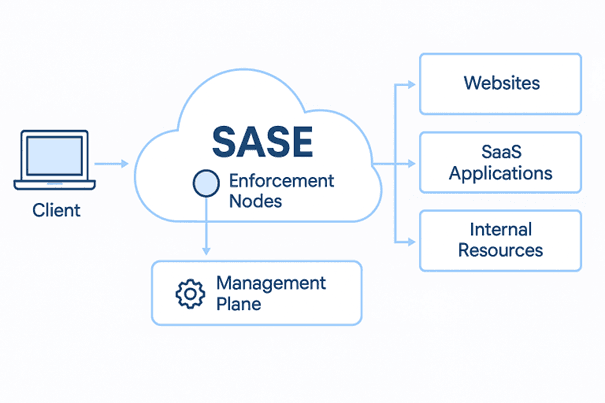
Der Secure Access Service Edge (SASE) ist heute für viele Unternehmen ein zentraler Baustein der Sicherheits- und Netzwerkarchitektur. Über die SASE‑Plattform laufen Webzugriffe, Verbindungen zu geschäftskritischen SaaS-Applikationen und der Zugriff auf interne Anwendungen via Zero Trust Network Access (ZTNA). Der Cloud‑Proxy schützt vor Bedrohungen, CASB und DLP sichern Daten und ZTNA ersetzt klassische VPN‑Infrastrukturen.
Das alles bietet starke Vorteile: einheitliche Policies, zentrales Logging, moderne Sicherheitstechnologien und eine global verteilte Infrastruktur. Doch genau diese zentrale Rolle macht SASE auch zu einem potenziellen Single Point of Failure. Ein Ausfall bedeutet nicht nur „das Internet ist langsam“ – sondern im schlimmsten Fall den Verlust sämtlicher Unternehmenszugänge.
Dieser Artikel beleuchtet, wie ein SASE‑Dienst aufgebaut ist, welche Ausfallszenarien realistisch sind und welche Notfallstrategien Unternehmen unbedingt einplanen müssen.
Aufbau eines SASE-Dienstes
Ein SASE-Dienst besteht im Kern aus zwei Bereichen:
Management Plane
Hier werden:
- Policies definiert
- Logs gesammelt
- Konfigurationen verteilt
- Connectoren und Enforcement Nodes verwaltet
Kurz: Die Management Plane steuert die gesamte Plattform – sie ist das „Gehirn“ des Systems.
Data Plane
Hier findet der eigentliche Datenverkehr statt:
- Clients verbinden sich mit Enforcement Nodes
- Authentisierung wird durchgeführt
- Policies werden angewendet
- Daten werden inspiziert, gefiltert und weitergeleitet
- Ereignisse werden geloggt
Komponenten wie Proxy, Firewall, DLP, Isolation, Sandboxing oder Malware‑Scanner laufen in der Data Plane.
Lokale Komponenten
Obige Komponenten werden durch den SASE-Anbieter betrieben.
Einige Bestandteile betreibt das Unternehmen selbst:
- Endpoint‑Agent zum Aufbau der SASE‑Verbindung
- Router / Gateways für Site‑to‑Cloud‑Tunnels (GRE, IPsec)
- ZTNA‑Connectoren für internen Applikationszugriff
Diese Komponenten sind ebenfalls kritisch und können Ausfälle verursachen.
Zugriff via SASE-Plattform
Wenn sich ein User/Client/Server über einen SASE-Provider mit einem Service verbinden will, so passiert grob folgendes:
- Eine Verbindung zu einem passenden Enforcement Node wird aufgebaut
- Der Zugriff wird authentisiert
- Access Policies werden angewendet
- Die übertragenen Daten werden kontrolliert
- Die entsprechenden Events werden protokolliert
Was passiert, wenn der SASE-Dienst ausfällt?
Nachfolgend die wichtigsten Ausfallszenarien – von häufig bis katastrophal.
Ausfall der Data Plane
Einzelner Enforcement Node fällt aus
Das ist unkritisch.
Grosse SASE‑Provider betreiben global dutzende bis hunderte redundante Enforcement Nodes.
Endpoint‑Agents messen die Latenz regelmässig und verbinden sich automatisch zum nächsten verfügbaren Node.
Dies passiert auch bei regulären Wartungen.
➡ Typisches Verhalten, keine Auswirkungen.
Überlastung und Latenzprobleme
Dies kommt häufiger vor als komplette Ausfälle und sind meistens sehr lokal begrenzt oder betrifft nur einzelne SaaS-Applikationen.
Mögliche Ursachen:
- Überlasteter SASE‑Node
- Routing‑Probleme zwischen ISP und SASE‑Node
- Probleme zwischen Enforcement Node und SaaS‑Ziel
Mögliche Lösungswege:
- Client‑Failover auf andere Nodes (automatisch oder manuell)
- Anpassung der Routing‑Policies durch den Internetprovider oder SASE-Anbieter
- Temporärer Wechsel auf entfernten Node zur Umgehung eines Internet‑Routingproblems
➡ Dies sind typische Performance‑Probleme, aber selten ein totaler Ausfall.
Worst Case: Alle Enforcement Nodes sind down
Dies ist extrem selten – aber möglich, z. B. durch:
- fehlerhafte Software‑Rollouts
- massive Management‑Plane‑Störungen
- DNS‑Fehler oder Zertifikatsprobleme
- Cloud‑Region‑Ausfälle
Wenn kein Node mehr zugewiesen werden kann, steht das Unternehmen still.
Empfohlene Massnahmen:
Monitoring und Frühwarnsystem
Unternehmen müssen unabhängig vom Provider erkennen können:
- Node‑Verfügbarkeit
- Authentisierungsfehler
- erhöhte Fehlerraten der Agenten
Eigener (privater) Enforcement Node
Falls vom Provider unterstützt:
- Clients verbinden sich mit einem privaten Node im Rechenzentrum
- Grosser Teil der Security bleibt erhalten
On‑Premises‑Fallback‑Proxy
Nicht ideal, aber möglich:
- Ein eigener “klassischer” Proxy für Notfälle
- Nachteile:
- separates (reduziertes) Regelwerk
- eingeschränkte Security-Funktionen
Direkter Internetzugang (nur als Notfalllösung!)
Nur zulässig, wenn:
- Firewalls entsprechend vorbereitet sind
- Endpoint Security vorhanden (EDR, DLP, DNS Filter)
- Endpoint Logging zentral erfolgt
Zweiter SASE‑Provider
Die ultimative, aber aufwändige Variante:
- zwei unabhängige SASE‑Clouds vom selben oder unterschiedlichen Anbietern
- vorbereitete Policies
- getestete Umschaltprozesse
Einige Anbieter bieten sogar „Disaster‑SASE“‑Abos an, die im Standby günstiger sind.
ZTNA‑Notfallzugang
Dieser ist besonders kritisch, da externe Mitarbeitende sonst keinen internen Zugriff mehr haben.
Fallback‑Optionen:
- lokaler ZTNA‑Node
- klassisches VPN
- Web‑Portal‑Zugänge
Ausfall des Identity Providers
Der Ausfall des Identity Providers ist ein oft unterschätzter Single Point of Failure!
Immer mehr Unternehmen nutzen Entra ID, Okta & Co. für:
- SASE‑Login
- SaaS‑Login
- Login an internen Applikationen
Fällt der IDP aus, steht die gesamte Unternehmens‑IT still.
Massnahmen:
- längere Token‑Lifetime für bereits eingeloggte Benutzer
- Anpassungen von Conditional‑Access-Regeln
- Fallback‑IDP
➡ Der IDP ist häufig der eigentliche „Single Point of Failure“ – nicht SASE.
Ausfall der Management Plane
Die Data Plane funktioniert weiterhin – aber:
- Policies können nicht angepasst werden
- Logs sind nicht sichtbar oder werden nicht gespeichert
- Compliance‑Nachweise fehlen
- Störungen können nicht analysiert werden
Best Practice:
- Logs zusätzlich in SIEM / Log‑Storage des Unternehmens speichern
- kritische Policies versionieren und offline ablegen
Ausfall lokaler Komponenten
Endpoint‑Agent
Typische Ursachen:
- OS‑Updates
- Konflikte mit EDR-Agents
- fehlerhafte Agent‑Rollouts
Empfehlungen:
- Testmatrix für Updates
- Canary‑Rollouts
- schnelle Rollback‑Möglichkeiten
ZTNA‑Connectoren
Diese sind für den Zugriff auf interne Applikationen entscheidend.
Wichtig:
- Redundanz (mehrere Connectoren)
- korrekte Dimensionierung
- geografische und topologische Verteilung
Zusammenfassung
Ein SASE‑Ausfall ist kein theoretisches Risiko. Je zentraler der Dienst wird, desto stärker steigt die Abhängigkeit.
Unternehmen brauchen zwingend:
- Monitoring
- Fallback‑Identity‑Mechanismen
- Dokumentierte Notfallprozesse
- Getestete Failover‑Pfade
- Optionen für externen Zugriff (ZTNA‑Fallback)
- Unabhängiges Logging
Ohne diese Massnahmen ist die Verfügbarkeit des gesamten Unternehmens gefährdet.